

 Talos
Talos Omni
Omni Kubernetes Guides
Kubernetes GuidesHow Omni rolls out configuration changes and upgrades
Omni applies configuration changes and Talos Linux upgrades to a machine set gradually, a few machines at a time, so the cluster keeps serving workloads while changes roll out. Configuration changes and upgrades are scheduled independently, each with its own concurrency limit:- Configuration changes (config patches and labels) are governed by
updateStrategy. - Talos Linux upgrades (version changes, extensions, and kernel arguments) are governed by
upgradeStrategy.
maxParallelism to roll changes out faster, or keep it low to limit how many machines are disrupted at once. See updateStrategy and upgradeStrategy in the cluster template reference.
Control plane machine sets always roll out one machine at a time, and this is not configurable. Omni also waits for etcd to be healthy before moving to the next control plane machine, so the control plane never loses quorum during a rollout.
When a machine needs both an upgrade and a configuration change, Omni upgrades it first and then applies the configuration change, because the new configuration may depend on the new Talos Linux version.
To stage a rollout, for example to validate a change on a few nodes before applying it across the cluster, lock the nodes you want to hold back.
Upgrade Talos Linux
To upgrade Talos Linux across all nodes in a cluster:- Sign in to Omni.
- Open Clusters from the left navigation.
- Select the cluster to upgrade.
- Click the upgrade indicator next to the current Talos version, or click Update Talos on the cluster panel.
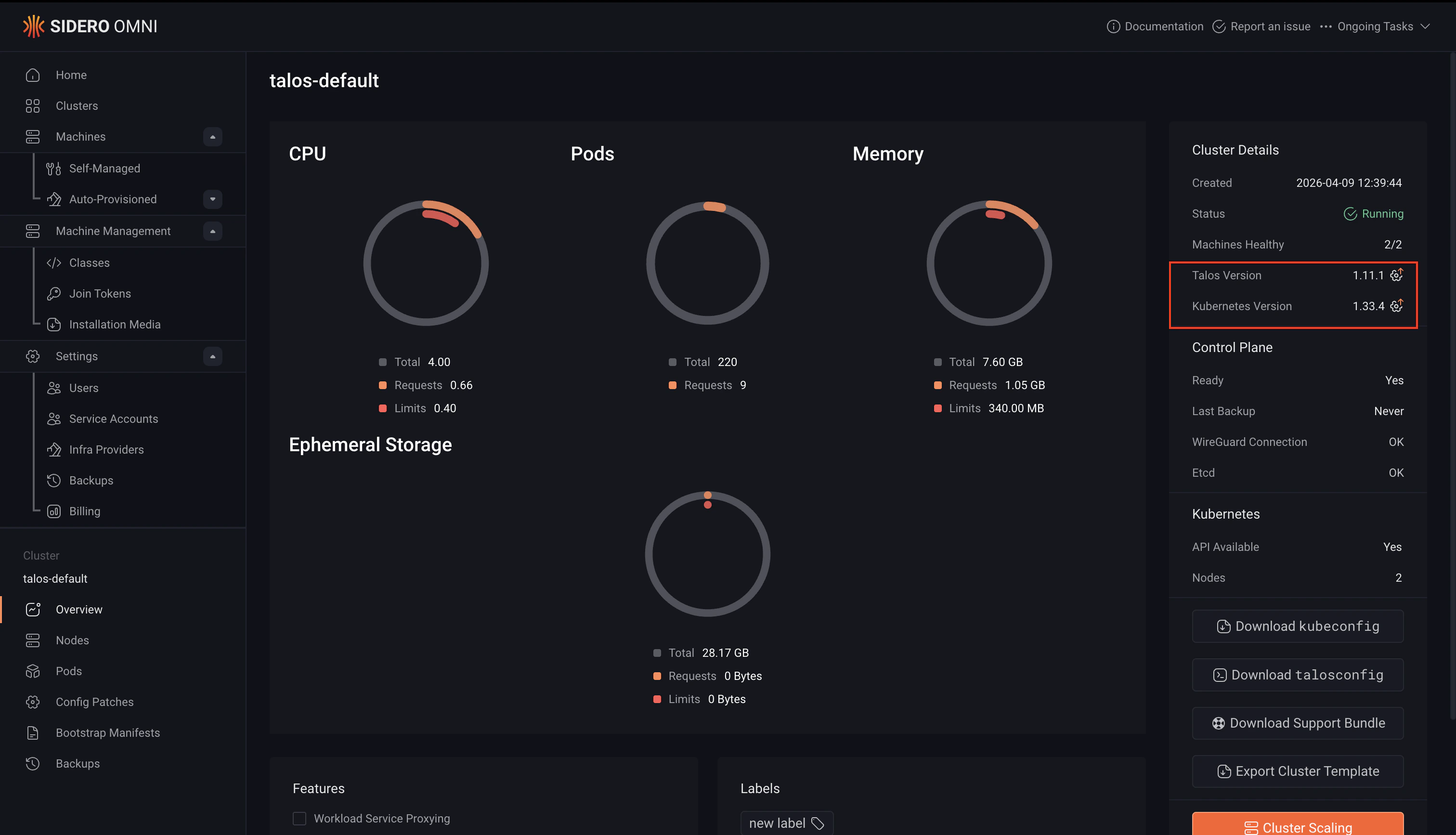
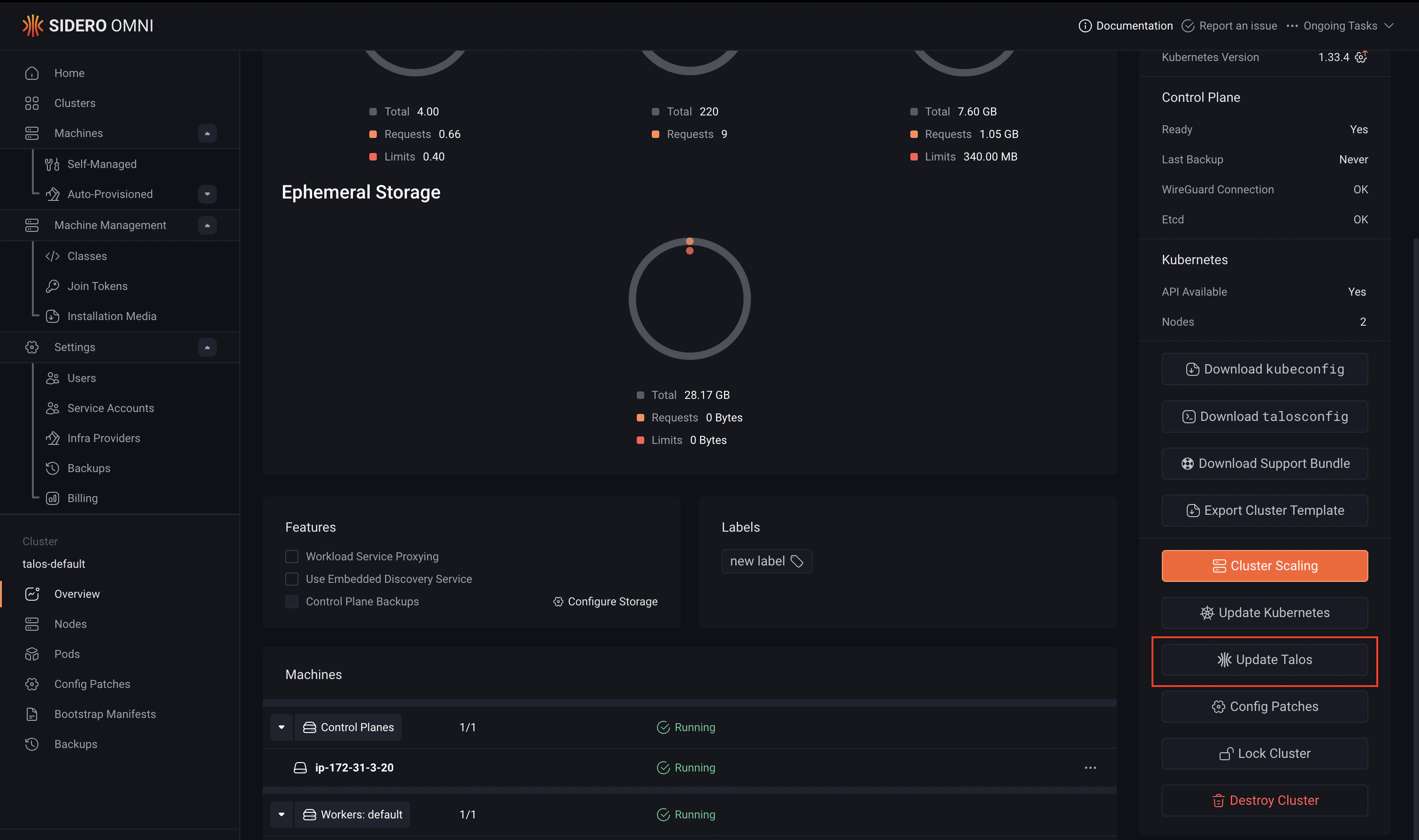
- Select the version to deploy.
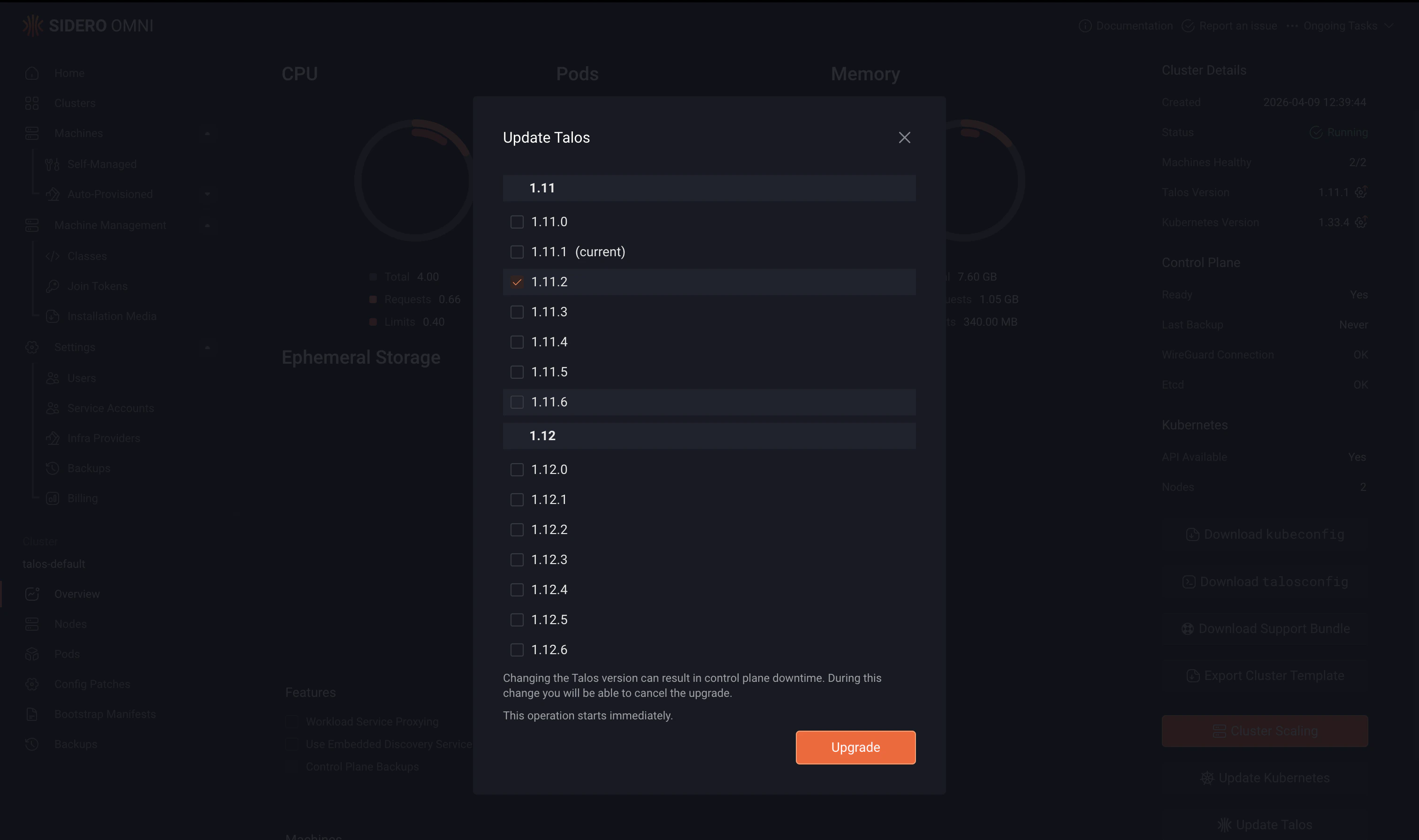
- Click Upgrade.
Omni only allows supported upgrade paths. In some cases, an intermediate upgrade may be required before upgrading to the most recent version.
What happens during a Talos Linux upgrade in Omni
Omni upgrades control plane nodes first, verifying that the etcd cluster is healthy and will remain healthy after each node leaves the etcd cluster before proceeding. For each node, Omni drains and cordons it, updates the OS, then uncordons it. All upgrades retain ephemeral data on the node. To control how many machines in a machine set are upgraded concurrently, configureupgradeStrategy in your cluster template.
If any of your workloads are sensitive to ungraceful shutdowns, configure the
lifecycle.preStop field in the Pod spec.Upgrade Kubernetes in your Omni clusters
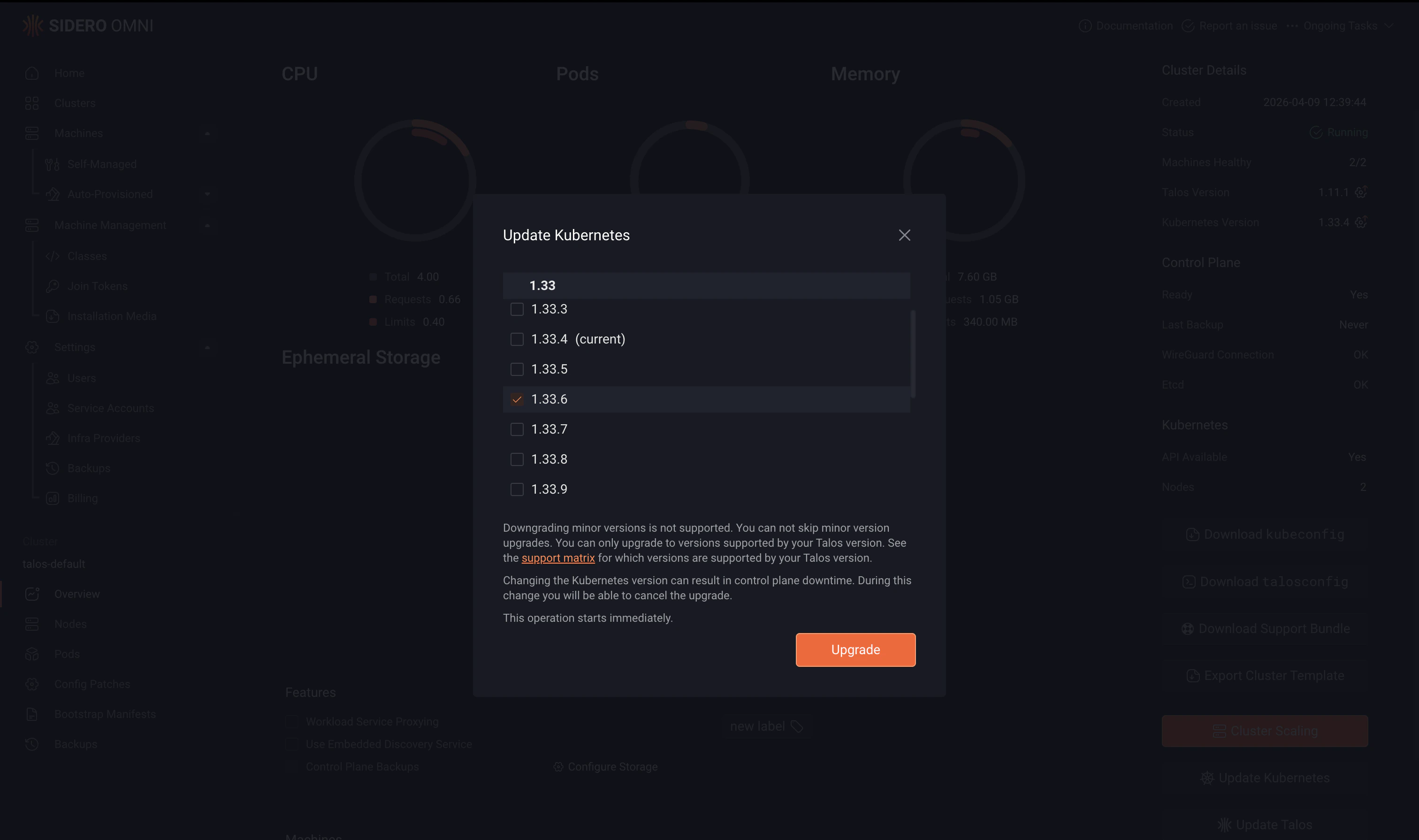
When a new Kubernetes version is available, Omni displays an upgrade indicator in the cluster overview. To upgrade Kubernetes:- Open the cluster.
- Click the upgrade indicator next to the Kubernetes version, or select Update Kubernetes.
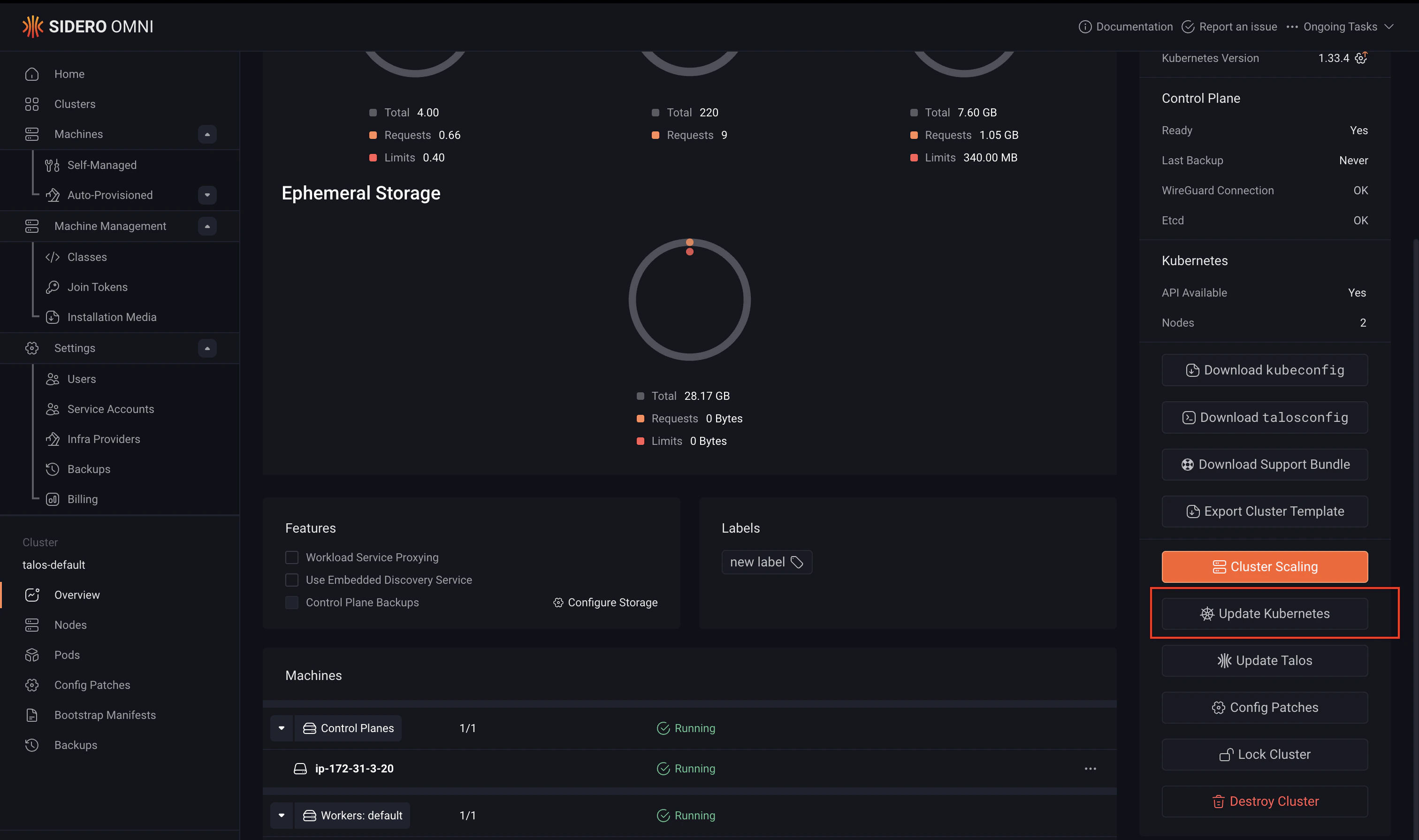
- Choose the target version and start the upgrade.
What happens during a Kubernetes upgrade
Kubernetes upgrades proceed in the following order:- Images for new Kubernetes components are pre-pulled to all nodes to minimize downtime and verify image availability.
- New static pod definitions are rendered and picked up by the kubelet. Omni waits for the change to propagate to the API server.
- The
kube-proxydaemonset is updated with the new image version. - The kubelet is updated on every node in the cluster.
Omni does not remove obsolete Kubernetes resources. Clean up unused resources manually if needed.
Apply updated Kubernetes manifests
Omni does not automatically apply updates to Kubernetes bootstrap manifests during an upgrade. Bootstrap manifests include cluster-critical components such as CoreDNS, kube-proxy, and the CNI plugin. This is intentional as it prevents Omni from overwriting changes you have made manually to those manifests. After the upgrade completes, Omni shows a diff of the proposed changes before applying them. Review these changes and apply only what is appropriate for your cluster. To do review these changes, open Bootstrap Manifests from the left navigation after each Kubernetes upgrade.
The
talosctl upgrade-k8s command provides a --dry-run flag that previews manifest changes before the upgrade runs. Omni surfaces these changes after the upgrade completes, but before they are applied.Locking nodes
Locking a node prevents it from receiving configuration updates, upgrades, or downgrades. This is useful when you want to roll out changes to a subset of nodes first, for example, to validate that your workloads behave correctly on the new version before updating the rest of the cluster.Note: Control plane nodes cannot be locked. Running a worker node on a higher Kubernetes version than the control plane is unsupported and may cause API version incompatibility.To lock a node, click the lock icon to the right of the node on the cluster overview page, or run the following command, replacing
<machine-id> with the ID of your machine:
Troubleshoot a stalled upgrade
Upgrades occasionally stall due to hardware issues, network interruptions, or unexpected machine behavior. This section covers what to do if an upgrade does not complete as expected, and how to recover if the cluster reaches a broken state.Before you start an upgrade
Before upgrading, verify that an etcd backup exists and completed successfully. Backups are your primary recovery path if an upgrade leaves the cluster in an unrecoverable state. To check the most recent backup status for your cluster, run the following command, replacing<cluster-name> with the name of your cluster:
If a node appears stuck during an upgrade
If a node is not progressing, wait before taking any action. Talos Linux performs several operations during an upgrade, including applying the new image, rebooting, and rejoining the cluster, and some steps can take longer than expected depending on hardware. If a node remains stuck after several minutes:- Check the machine status in the Omni UI. A status of Rebooting or Installing indicates the upgrade is still in progress.
-
Check the machine logs in the Omni UI or by running the following command, replacing
<machine-id>with the ID of your machine: - If you have access to a serial or VNC console for the machine, use it to inspect the machine state directly. This is especially useful when Talos is unresponsive, since Talos does not allow SSH access by design.
- If the upgrade cannot proceed, cancel it from the Omni UI.
What not to do during a stalled upgrade
Avoid the following actions while an upgrade is in progress, as they can break etcd quorum and leave the cluster in an unrecoverable state:- Do not delete machines out-of-band. Deleting a VM directly from your infrastructure provider (such as OpenStack or AWS) without going through Omni leaves Omni waiting for a machine that no longer exists. This disrupts the upgrade and can break control plane quorum.
- Do not add control plane nodes to resolve a quorum issue. Adding machines while the control plane is in a broken state does not restore quorum and makes the situation harder to recover from.
-
Do not run
kubectl delete nodeon a control plane node. This removes the node from Kubernetes without removing it from Omni or etcd, which can break quorum.